



整理后的项目代码
阅读:2025 分享到我们在此采用面向对象的方法重新整理自动赚钱项目,并且进行了模块化,整个项目含有
component_tools 文件夹、img 文件夹、
settings.py文件、txviews.py 和
wxgzh.py,整个项目的代码结构图如下。
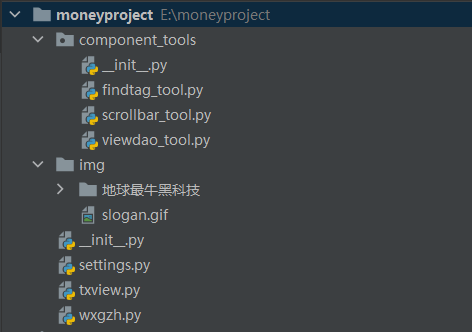
在component_tools 文件夹类含有三个文件分别为findtag_tool.py,
scrollbar_tool.py,viewdao_tool.py。其中findtag_tool.py
文件中是我们封装的安全健壮的鼠标和键盘操作的函数;scrollbar_tool.py
文件中是下拉滚动条的代码,viewdao_tool.py 文件中是数据库操作的代码。
在img 文件中含有一个 地球最牛黑科技 的文件和一个 slogan
文件。其中 地球最牛黑科技 文件夹中存放我们下载视频题材的图片;slogan
文件是我们公众号中插入的一个让用户关注我们公众号的gif,如下图(当然你也可以不需要这一项)。

在settings.py文件中,我们把定义的路径变量都存放在里面;txview.py
文件中是爬取腾讯视频的代码;wxgzh.py文件中是自动上传和发布公众号的代码。
废话不多说,下面是整个项目的代码。
findtag_tool.py文件
import time from selenium.webdriver.common.action_chains import ActionChains def inter_time_find_tag(driver, tagname, strtag, intertime=1, count=30000): nowcount = 0 while nowcount < count: time.sleep(intertime) try: result = driver.find_element_by_xpath(strtag) print("规定时间内找到:" + tagname) return result # 找到tag就返回 except: nowcount += 1 print("没找到" + tagname + str(nowcount) + "次") print("规定时间次数内没找到:" + tagname) def safeclick(tag, info="noinfo"): while True: try: tag.click() break except: print(info) time.sleep(1) def safesend_keys(tag, data, info="senderror"): while True: try: tag.send_keys(data) break except: print(info) time.sleep(1) def moveandclick(driver, movetag, clicktag): while True: ActionChains(driver).move_to_element(inter_time_find_tag(driver, movetag[0], movetag[1])).perform() try: inter_time_find_tag(driver, clicktag[0], clicktag[1]).click() break except: print("重新移动鼠标") time.sleep(1)
scrollbar_tool.py文件
import random import time def pullscrool(driver, mintime, maxtime): js = ''' function RandomNumBoth(Min, Max){ var Range = Max - Min; var Rand = Math.random(); var num = Min + Math.round(Rand * Range); return num;} var oldscrollpos = window.scrollY; var step = RandomNumBoth(500, 800); window.scrollBy(0, step); var newscrolpos = window.scrollY; if(oldscrollpos == newscrolpos) return false; else return true; ''' for count in range(150): driver.execute_script(js) time.sleep(random.uniform(mintime, maxtime)) # 取随机值更人性化
viewdao.py文件
import pymysql class viewDao: def __init__(self): # 数据名字和数据库连接密码要换掉 self.gxviewdb = pymysql.connect(user='birdpython', # 登录数据库的用户名(换成你自己的) passwd='laoniao', # 登录数据库的密码(换成你自己的) db='gxview', # 要操作的数据库(换成你自己的) host='88.88.88.88', # 登录数据库的IP地址(换成你自己的) charset='utf8') # 指定编码格式为utf-8,否则显示乱码 def saveview(self, views): sql = 'insert gxviewtable(viewname, viewlink, viewimglink, viewlength, viewtype) values ("%s", "%s", "%s", "%s", "%s")'%(views[0], views[1], views[2], views[3], views[4]) cursor = self.gxviewdb.cursor() try: cursor.execute(sql) self.gxviewdb.commit() except: print("错误原因视频名字不合规范:", views[0]) cursor.close() def changeview(self, viewdatas): viewnameindex = 2 for data in viewdatas: sql = "UPDATE gxviewtable SET viewused = 1 WHERE viewname = '%s'" % (data[viewnameindex]) try: cursor = self.gxviewdb.cursor() cursor.execute(sql) # 提交到数据库执行 self.gxviewdb.commit() except: # 发生错误时回滚 self.gxviewdb.rollback() print("数据库已经修改") def savetest(self, i): pass def findviewunused(self, viewtype, viewcount): cursor = self.gxviewdb.cursor() sql = "select * from gxviewtable where viewused=0 and viewtype='%s' limit %d" % (viewtype, viewcount) cursor.execute(sql) viewtuple = cursor.fetchall() cursor.close() return viewtuple def findviewname(self): cursor = self.gxviewdb.cursor() sql = "select viewname from gxviewtable" cursor.execute(sql) viewtuple = cursor.fetchall() cursor.close() return viewtuple def closegxviewdb(self): self.gxviewdb.close()
settings.py文件
import os # 项目根目录 basedir = os.path.dirname(os.path.abspath(__file__)) # 图片根目录 imgdir = os.path.join(basedir, "img") # 公众号的下载的图片存放路径 hkj_dir = os.path.join(os.path.join(imgdir, "地球最牛黑科技"), "素材")
txview.py文件
from selenium import webdriver from bs4 import BeautifulSoup from component_tools.scrollbar_tool import pullscrool from component_tools.viewdao_tool import viewDao class TXView(object): def __init__(self, url, viewtype): self.url = url self.viewtype = viewtype self.maxviewcount = 8 # 最大视频个数 self.viewmintime = "00:50" # 视频最小时长 self.viewmaxtime = "03:00" # 视频最大时长 self.viewcount = 0 self.viewdriver = webdriver.Chrome(executable_path="C:/driver/chromedriver.exe") self.gxviewdb = viewDao() self.gxviewdbnames = self.gxviewdb.findviewname() def saveview(self, viewslist): # 存储视频到数据库 for item in viewslist: self.gxviewdb.saveview(item) def judgeviewtime(self, viewtime): # 筛选不符合时长的视频 return viewtime >= self.viewmintime and viewtime <= self.viewmaxtime def judgeviewrepeat(self, viewname): # 筛选重复的视频 return viewname not in self.gxviewdbnames def getview(self, viewslist): # 下来滚动条 pullscrool(self.viewdriver, 0.03, 0.07) # 爬取所有视频标签 viewstag = self.viewdriver.find_elements_by_class_name("list_item") # 提取每个视频的信息(视频名称,视频链接,视频图片,视频时长) for item in viewstag: viewname = item.find_element_by_tag_name('img').get_attribute("alt") # 视频名称 viewlink = item.find_element_by_class_name('figure').get_attribute("href") # 视频链接 viewimg = item.find_element_by_tag_name('img').get_attribute("src") # 视频图片链接 viewtime = item.find_element_by_class_name('figure_caption').text # 视频时长 # 去掉一些不友好的标点符号 viewname = viewname.replace("\"", u"”") \ .replace("\'", u"’").replace(":", u":").replace("?", u"?") \ .replace(" ", u"").replace("|", u",").replace(u" ", u"") \ .replace(u"❤", u"").replace(u"➕", u"").replace(u"#", u"") \ .replace("/", u"-") # 判断视频时长和数据是否已在数据库中 if self.judgeviewtime(viewtime) and self.judgeviewrepeat((viewname,)): viewslist.append([viewname, viewlink, viewimg, viewtime, self.viewtype]) # 判断爬够8个视频,退出爬取腾讯视频逻辑 self.viewcount += 1 # 每次循环已经解析过的视频个数加1 if self.viewcount >= self.maxviewcount: # 如果够8个就退出循环 break def start(self): viewslist = [] self.viewdriver.get(self.url) # 打开腾讯视频网站 self.viewdriver.maximize_window() # 最大化浏览器 self.getview(viewslist) # 爬取腾讯视频 self.saveview(viewslist) # 存储视频到数据库 self.gxviewdb.closegxviewdb() # 关闭数据库 self.viewdriver.close() # 关闭chromedriver驱动器
wxgzh.py文件
import os import settings import time import requests from io import BytesIO import threading from PIL import Image from txview import TXView from component_tools.findtag_tool import inter_time_find_tag, safeclick, safesend_keys, moveandclick from component_tools.scrollbar_tool import pullscrool from component_tools.viewdao_tool import viewDao from selenium import webdriver class WXGXH: def __init__(self, wxobject): # 给requests下载图片用的 self.headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36"} self.firstimginsertflag = True # 上传第一个页面时的弹窗标记 self.imagedocount = "first" self.image = {"first": {"width": 407, "hight": 228}, "other": {"width": 229, "hight": 228}} self.url = wxobject['url'] self.dirpath = wxobject["dirpath"] # 图片存放路径 self.viewtype = wxobject['viewtype'] # 视频类型 self.username = wxobject["username"] # 公众号登录名 self.password = wxobject["password"] # 公众号密码 self.slogan1 = wxobject['slogan1'] self.slogan2 = wxobject['slogan2'] self.sucflag = True self.loginurl = "https://mp.weixin.qq.com/" self.viewcount = 8 self.title = {'viewdate': 1, "viewname": 2, "viewlink": 3, "viewimglink": 4} def setflag(self, flag): self.sucflag = flag # 自动登录 def wxlogin(self): self.wxdriver = webdriver.Chrome( executable_path="C:/driver/chromedriver.exe") self.wxdriver.get(self.loginurl) self.wxdriver.maximize_window() # 虽然找到该元素,但不最大化显露出来没法点击 safeclick(inter_time_find_tag(self.wxdriver, "使用帐号登录", '//a[@class="login__type__container__select-type"][text()="使用帐号登录"]'), "点击使用账号登录失败") safesend_keys(inter_time_find_tag(self.wxdriver, "用户名", "//input[@name='account']"), self.username, "输入用户名失败") safesend_keys(inter_time_find_tag(self.wxdriver, "密码", "//input[@name='password']"), self.password, "输入密码失败") while self.sucflag: try: self.wxdriver.find_element_by_xpath("//div[@class='js_wording']") # 没有进入 self.setflag(False) # 登录成功,退出循环 except: safeclick(inter_time_find_tag(self.wxdriver, "登录", "//a[@class='btn_login']"), "点击登录失败") time.sleep(2) # 页面并没有马上出来,需要等待 # 进入iframe def __windowtoframe(self, content): iframe = inter_time_find_tag(self.wxdriver, "编辑文档", '//iframe[@id="ueditor_0"]') self.wxdriver.switch_to.frame(iframe) safesend_keys(inter_time_find_tag(self.wxdriver, "iframe的body", '//body'), content, "输入空格占位失败") # 插入让用户关注我们公众号的gif def __insertslogan(self): safeclick(inter_time_find_tag(self.wxdriver, "图片", '//li[@id="js_editor_insertimage"]')) safeclick(inter_time_find_tag(self.wxdriver, "从图片库选择", '//li[@class="tpl_dropdown_menu_item"][text()="从图片库选择"]')) safeclick(inter_time_find_tag(self.wxdriver, "点击slogan", '//strong[text()="slogan"]')) # 因为slogan和全部图片有共同点 inter_time_find_tag(self.wxdriver, "判断slogan选中", '//strong[text()="slogan.gif"]') safeclick(inter_time_find_tag(self.wxdriver, "选中图片", '//span[@class="image_dialog__checkbox"]')) safeclick(inter_time_find_tag(self.wxdriver, "点击确定slogan", '//*[@id="vue_app"]/div[3]/div[1]/div/div[3]/div[2]/button')) # 增加新的一项素材 def __newcontent(self): # 下拉左边滚动条 self.wxdriver.execute_script("document.getElementById('js_mp_sidemenu').scrollTop=1200") self.imagedocount = "other" # 功能:移动后安全点击(程序移动了,用户有时候再次移动鼠标失去焦点,导致点击失败。该函数可以判断在点击失败后,重新移动鼠标) moveandclick(self.wxdriver, ("点击+号", '//*[@id="js_add_appmsg"]/i'), ("增加一条图文消息", '//i[@class="icon-svg-editor-appmsg"]')) # 判断公众号是否发布成功 def iscomplete(self, viewdatas): if inter_time_find_tag(self.wxdriver, "是否发布", "//span[text()='首页']"): viewDao().changeview(viewdatas) def __judgecontents(self, count, viewdatas): # 有时候完成按钮消失后,回到主页面可能会延迟 # 完成按钮消失,点击才可以保存 while inter_time_find_tag(self.wxdriver, "完成按钮", '//button[text()="完成"]/', 1, 1): pass if count < self.viewcount - 1: while True: tagsave = inter_time_find_tag(self.wxdriver, "保存", '//button[text()="保存"]', 1, 1) or \ inter_time_find_tag(self.wxdriver, "保存为草稿", '//span[text()="保存为草稿"]', 1, 1) if tagsave: break safeclick(tagsave) self.__newcontent() else: while True: tagsave = inter_time_find_tag(self.wxdriver, "保存并群发", '//button[text()="保存并群发"]', 1, 1) or \ inter_time_find_tag(self.wxdriver, "群发", '//span[text()="群发"]', 1, 1) if tagsave: break safeclick(tagsave) safeclick(inter_time_find_tag(self.wxdriver, "群发", '//button[text()="群发"]')) safeclick(inter_time_find_tag(self.wxdriver, "继续群发", '//button[text()="继续群发"]')) self.iscomplete(viewdatas) # 下载图片 def __imgdo(self, viewimglink, viewname, count): filepath = os.path.join(self.dirpath, viewname + '.png') f = BytesIO(requests.get(viewimglink, headers=self.headers).content) img = Image.open(f) img.resize((self.image[self.imagedocount]["width"], self.image[self.imagedocount]["hight"]), Image.ANTIALIAS).save(filepath) f.close() # 下拉滚动条 pullscrool(self.wxdriver, 0.003, 0.1) # 封面和摘要 moveandclick(self.wxdriver, ("选择封面", '//span[text()="拖拽或选择封面"]'), ("从图片库选择", '//*[@id="js_cover_null"]/ul/li[2]/a')) safeclick(inter_time_find_tag(self.wxdriver, "今日图片", '//strong[text()="今日图片"]'), "点击今日图片失败") # 因为今日图片和全部图片有共同点 while inter_time_find_tag(self.wxdriver, "判断今日图片选中", '//strong[text()="今日图片"]/..').get_attribute( "class") != "weui-desktop-menu__link weui-desktop-menu__link_current weui-desktop-menu__link-self": pass inter_time_find_tag(self.wxdriver, "从本地上传视频图片", '//*[@id="vue_app"]/div[3]/div[1]/div/div[2]/div[1]/div/div[2]/div/div[1]/div/div/div[2]/div[2]/input').send_keys( filepath) while inter_time_find_tag(self.wxdriver, "文件是否传输完成下一步按钮生效", '//button[text()="下一步"]').get_attribute( "class") != "weui-desktop-btn weui-desktop-btn_primary": pass # 下一步按钮生效,不然点击没效果 safeclick(inter_time_find_tag(self.wxdriver, "文件是否传输完成下一步按钮生效", '//button[text()="下一步"]')) safeclick( inter_time_find_tag(self.wxdriver, "点击视频图片完成", '//*[@id="vue_app"]/div[3]/div[1]/div/div[3]/div[2]/button')) # 开始上传爬取的腾讯视频题材到公众号 def dowxcontent(self, viewdatas): for count, viewdata in enumerate(viewdatas): viewname = viewdata[self.title["viewname"]] viewlink = viewdata[self.title["viewlink"]] viewimglink = viewdata[self.title["viewimglink"]] # 输入标题 safesend_keys(inter_time_find_tag(self.wxdriver, "请在这里输入标题", '//textarea[@placeholder="请在这里输入标题"]'), viewname, "输入标题失败") # 切换到iframe 的driver self.__windowtoframe("") # 切换回来,此处保留 insertslogan 功能 self.wxdriver.switch_to.default_content() self.__insertslogan() # 切换到iframe 的driver self.__windowtoframe(" ") # 切换回来 self.wxdriver.switch_to.default_content() safeclick(inter_time_find_tag(self.wxdriver, "视频", '//li[@id="js_editor_insertvideo"]')) safeclick(inter_time_find_tag(self.wxdriver, "视频链接", '//*[@id="vue_app"]/div[3]/div[1]/div/div[2]/div/div[1]/div[1]/ul/li[2]/a')) safesend_keys( inter_time_find_tag(self.wxdriver, "输入视频链接", '//input[@placeholder="支持微信公众号文章链接,视频详情页链接和腾讯视频链接"]'), viewlink, "输入视频链接失败") safeclick(inter_time_find_tag(self.wxdriver, "点击确定视频", '//*[@id="vue_app"]/div[3]/div[1]/div/div[2]/div/div[3]/form/div/div/div[2]/button')) safeclick(inter_time_find_tag(self.wxdriver, "点击确定视频", '//*[@id="vue_app"]/div[3]/div[1]/div/div[3]/div/div[2]/button')) self.__imgdo(viewimglink, viewname, count) self.__judgecontents(count, viewdatas) # 找倒所有新的tab页 def wxfindtab(self): all_handles = self.wxdriver.window_handles # 获取所有窗口句柄 for handle in all_handles: self.wxdriver.switch_to.window(handle) if inter_time_find_tag(self.wxdriver, "请在这里输入标题", '//input[@placeholder="请在这里输入标题"]', 1, 1): break # 点击素材管理 def click_scmange(self): # 由其它微信扫描进来的,查找元素要调用一次 self.wxdriver.maximize_window() # 虽然找到该元素,但不最大化显露出来没法点击 safeclick(inter_time_find_tag(self.wxdriver, "图文消息", '//*[@id="app"]/div[2]/div[4]/div[2]/div/div[1]', 1, 3600)) # 从数据库中获取所有爬过的视频 def getdatafromviewdao(self): viewdatas = viewDao().findviewunused(self.viewtype, self.viewcount) return (True, viewdatas) if len(viewdatas) == self.viewcount else (False,) # 开始爬取视频和上传公众号 def startdowx(self): viewdatastuple = self.getdatafromviewdao() if False == viewdatastuple[0]: # 数据库中视频量不够开始爬视频 TXView(self.url, self.viewtype).start() self.startdowx() else: # 数据库中已有8个未发布的视频,可以直接上传公众号 print("开始编辑微信公众号") self.wxlogin() self.click_scmange() self.wxfindtab() self.dowxcontent(viewdatastuple[1]) # 本地图片使用完后清理掉 def clearimg(wxobject): del_list = os.listdir(wxobject["dirpath"]) for f in del_list: file_path = os.path.join(wxobject["dirpath"], f) if os.path.isfile(file_path): os.remove(file_path) # 开始行动 def dostart(wxobject): print("开始") clearimg(wxobject) # 清理本地磁盘图片 wxgzh = WXGXH(wxobject) wxgzh.startdowx() # 初始化账户和腾讯视频网站以及图片存放路径 def initwxobjectdata(): # 返回一个元组,支持同时爬取多个公众号 return ( {"url": "https://v.qq.com/channel/tech?_all=1&channel=tech&icolumn=-1&itype=6&listpage=1&sort=40", "viewtype": u"地球最牛黑科技", "slogan1": u'【点击关注左上方蓝色标题「地球最牛黑科技', "slogan2": u'」天天看最新黑科技】', "username": "xxx@126.com", "password": "xxx", # 用户名和密码换成你自己的 "dirpath": settings.hkj_dir}, ) if __name__ == '__main__': wxobjects = initwxobjectdata() for wxobject in wxobjects: t1 = threading.Thread(target=dostart, args=(wxobject,)) t1.start()
另外的惊喜,我们的程序支持同时操作多个公众号(同时爬视频和同时上传公众号)。程序运行后,大家就可以躺着赚钱了!!!赶紧行动起来吧!!!
如果以上内容对您有帮助,请老板用微信扫一下赞赏码,赞赏后加微信号 birdpython 领取免费视频。






请登录后评论